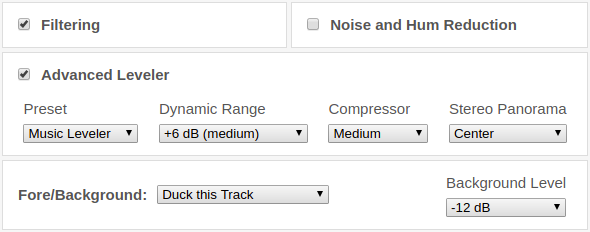
Responding to your feedback, we are now proud to present new separate parameters for noise, reverb, and breath reduction to give you more flexible control for your individual, best output results.
Find all the new parameters below and listen to the Audio Examples to get a closer impression of the upgrade.

What's the update about?
Before
Previously, you could only set the Denoising Method and one reduction amount, that was used for all elements.
Depending on the selected method, you were already able to decide whether music, static, or changing noises should be removed, but there was no setting ...