Following current standards, loudness normalization is applied regardless of the content of a production.
Cinematic content, i.e. productions with a high loudness range, can benefit from dialog loudness normalization.
At Auphonic, we are introducing a classifier for
automatic speech loudness normalization,
and our processing stats now provide level statistics for dialog and music as well as the overall production.
 Photo by Dima Pechurin.
Photo by Dima Pechurin.
Loudness of Cinematic Content
We have discussed the issue extensively, but it’s still true: getting the levels of your production right is difficult. It’s especially challenging when you work with music, sound effects and speech, some of it louder, some quieter. When the European Broadcasting Union (EBU) released the recommendation R 128, standardizing loudness normalization to -23 LUFS program loudness, it helped in making programs more evened out overall. However, loud music or sound effects and quiet speech combined can still lead to a production that conforms with the standard.
Now, new recommendations emerge that provide more guidance. In short: normalize the loudness based on speech content and allow music and sound effects to fall into a loudness range around the speech level - ideally within the loudness comfort zone. New algorithms in Auphonic allow you to do this automatically. It’s especially relevant for cinematic content, which can include feature films and TV series but radio dramas as well, i.e. audio with a high loudness range.
New Netflix Recommendation
One of the drivers behind dialog loudness normalization is Netflix, or, to be precise, the team around Netflix’s manager of sound technology, Scott Kramer. They apparently were unhappy with how their content sounded under Netflix’s previous spec, as Scott describes on the blog Pro Tools Expert:
We measured our content which was compliant for the -24 LKFS +/- 2 LU full program spec, and found that dialog levels clustered around -27 LKFS.
(Note: LKFS is synonymous with LUFS.)
Dialog was relatively quiet, while louder music and sound effects lifted the overall loudness of the production. To some extent, this loudness dynamic is wanted, of course. As we described before, it can be more exciting to listen to. But it can also result in something that frequently annoys viewers: when they set the volume level of their home entertainment system so that it’s pleasant for dialog, they often have to lower the volume for scenes with a lot of sound other than speech, e.g., action scenes.
We believe that dialog is the anchor element around which FX and Music are mixed. Just as the viewer sets their level based on dialog, mixers most often set a room level based on where the dialog “feels right.“
As a consequence, Netflix adapted their spec. The very first sentence of the Netflix Sound Mix Specifications now reads:
Average loudness must be -27 LKFS +/- 2 LU dialog-gated.
Dialog-gated being the crucial word here, making all the difference. Elsewhere it might be called anchor-based normalization or voice/speech loudness, and at Auphonic we call it dialog loudness. What it means is that a certain “anchor signal”, i.e. speech, is used for normalization instead of the mixed signal.
The EBU (European Broadcasting Union) is working on a similar supplement to EBU R 128 for cinematic content, also considering anchor-based loudness normalization.
Dialog Loudness Normalization in Auphonic
With Auphonic, you can now choose between two normalization methods: dialog loudness or the overall program loudness, if you’ve turned on our advanced algorithms:
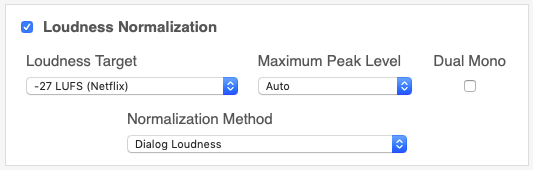
A prerequisite is that you can actually evaluate the speech signal separately from music and sound effects. The Auphonic algorithm uses a classifier that analyzes your audio and automatically puts segments of it either into the speech or into the non-speech bucket.
Multitrack productions offer an even more refined approach. Separate tracks or stem files make it easy to keep dialog and other signals separate and hence evaluate and process them separately.
New Processing Statistics
We also display some new loudness-related processing statistics now. Once your production is finished, have a look at the stats table (click Show Stats below the result waveforms).
Singletrack Stats
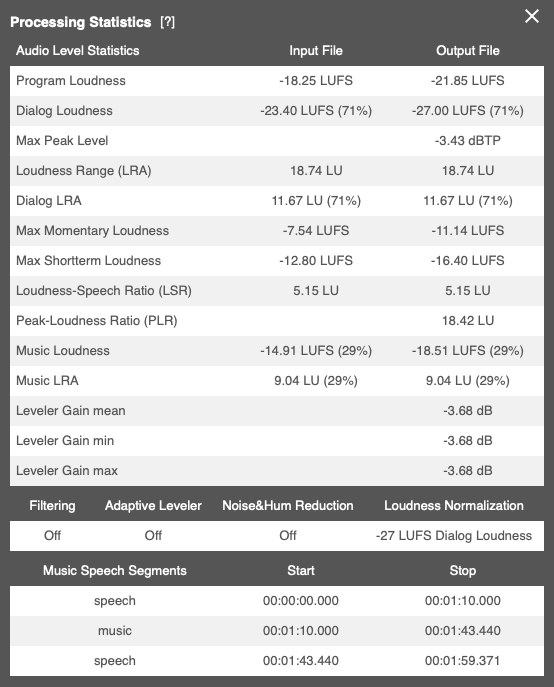
You’ll see three pairs of values for the loudness of your production:
- Program Loudness and Loudness Range (LRA):
the overall loudness and loudness range - Dialog Loudness and Dialog LRA:
the loudness and loudness range of speech segments - Music Loudness and Music LRA:
the loudness and loudness range of non-speech segments.
A percentage following the loudness and LRA values indicates what portion of your production has been classified as speech or music.
In the screen shot above, the output file has been normalized to -27 LUFS dialog loudness (second row). 71 percent of the production has been classified as speech. The program loudness is much higher than the dialog loudness, at -21.85 LUFS, caused by comparatively loud music (Music Loudness: -18.51 LUFS). The Dialog Loudness Range of 11.67 LUFS is pretty high, as is the overall Loudness Range.
Netflix, for instance, recommends a loudness range (LRA) of 4 to 18 LU for the overall program, but 7 LU or less for dialog.
We can address these issues by turning on Auphonic’s Adaptive Leveler:
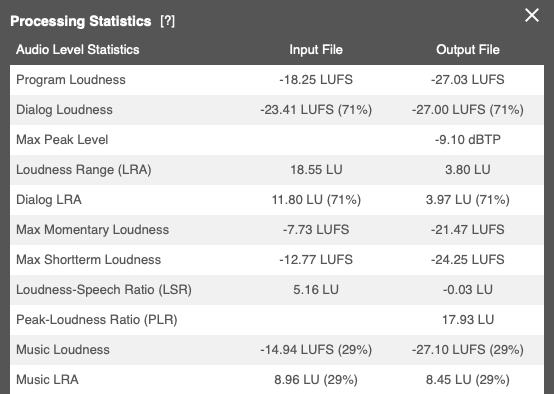
Now, the production yields a result that is much more enjoyable to listen to, with a much smaller overall and Dialog Loudness Range, while the Music LRA hasn’t changed much.
Multitrack Stats
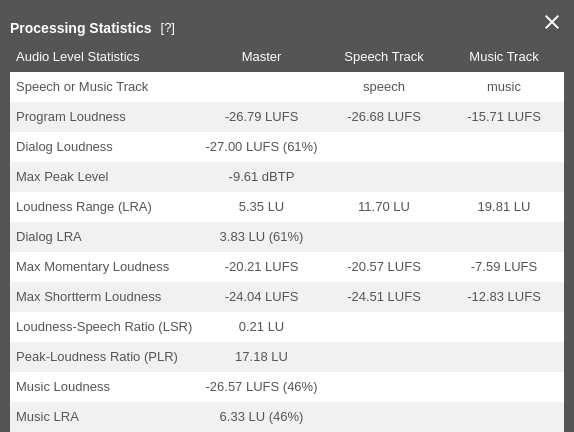
These statistics are from the same audio as above, but as a multitrack production. As you can see, our algorithm has automatically classified one track as speech and the other as music. If you look closely, you’ll notice that speech and music segments add up to more than 100%. This is because the segments overlap.
We turned on the Adaptive Leveler, which results in a much better Dialog Loudness Range. The Dialog Loudness is now not too far off the overall loudness. There’s a specific value to indicate this:
- Loudness-Speech Ratio (LSR):
the difference in loudness between the speech segments and the overall production.
A high Loudness-Speech Ratio means that speech segments are much quieter than average, impacting their intelligibility. A LSR of 5 LU or less is best for most productions.
Summary
Anchor-based loudness normalization is especially relevant for
cinematic content or audio with a big loudness range.
This ensures that dialog is always intelligible and that different productions have a similar speech loudness, while still allowing music and effects to be louder and have a bigger loudness range - ideally within the loudness comfort zone.
New tools at Auphonic can do that automatically for you now, or you might want to manually check our loudness-related processing statistics for quality control.